
10 Datadog Monitoring Tips for SMB Success
Explore essential monitoring tips for SMBs using Datadog to optimize performance, enhance security, and manage costs effectively.

Datadog simplifies monitoring for small and medium-sized businesses (SMBs), helping you manage cloud infrastructure, improve performance, and reduce costs. Here’s what you’ll learn:
- Set up effective alerts: Use dynamic thresholds and severity levels to avoid alert fatigue.
- Build dashboards: Track key metrics like CPU usage, response times, and business transactions.
- Optimize costs: Spot unused resources and automate scaling to save money.
- Enhance security: Leverage threat detection, compliance tools, and automated responses.
- Plan capacity: Use historical data and machine learning to forecast future needs.
- Utilize tagging: Organize resources with clear tags for easier monitoring.
- Streamline incident management: Integrate alerts with tools like Slack or Jira for faster resolutions.
- Leverage training resources: Access Datadog’s Learning Center for role-specific courses.
Quick Comparison of Key Features
| Feature | What It Does | SMB Benefit |
|---|---|---|
| Alerts | Dynamic thresholds, severity levels | Avoid noise, prioritize critical issues |
| Dashboards | Customizable widgets | Monitor performance and business metrics |
| Cost Optimization | Detect unused resources | Save money on cloud expenses |
| Security Tools | Threat detection, compliance checks | Protect data and meet regulatory needs |
| Capacity Planning | ML-based forecasts | Prevent resource shortages |
| Tagging | Organize resources | Simplify troubleshooting |
| Incident Management | Integrations with tools like Jira | Faster issue resolution |
| Learning Resources | Role-based training paths | Improve team expertise |
Datadog is priced at $15 per host/month, making it a cost-effective solution for SMBs looking to improve monitoring and performance. Follow these tips to make the most of your investment and ensure your infrastructure runs smoothly.
Datadog Tutorials | Alerting and Monitoring
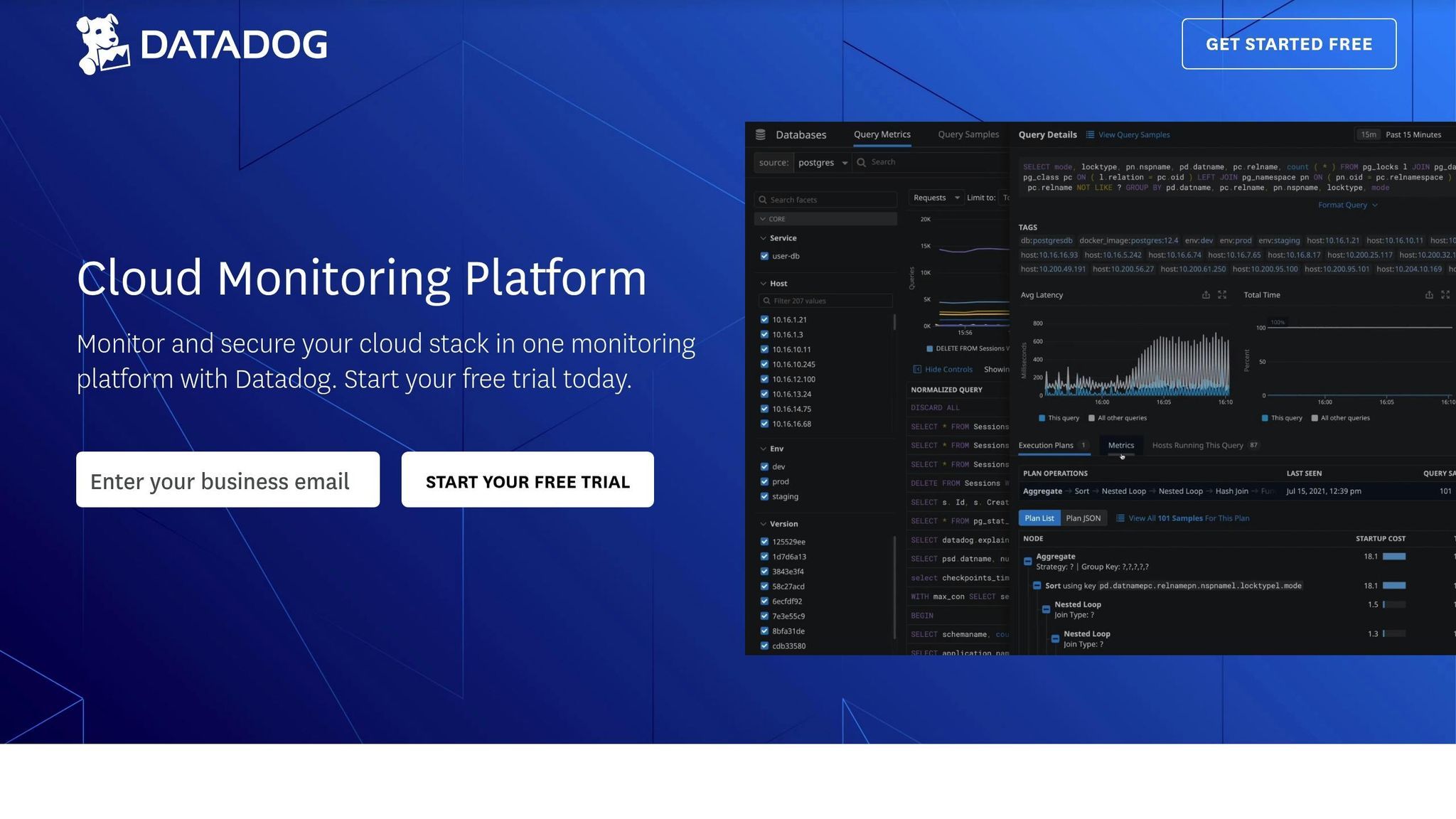
Basic Datadog Setup
Start by carefully planning your Datadog setup. Install the lightweight Datadog Agent, which uses approximately 0.08% CPU.
Install the Datadog Agent across various environments, including local hosts (Windows, macOS), containers (Docker, Kubernetes), or on-premises data centers. Then, connect your cloud services and organize your resources effectively.
Setting Up Tags and Cloud Integrations
Datadog automatically imports tags from platforms like AWS, Kubernetes, and Chef, making it easier to add context to your monitoring data.
"With tags, you can organize complex data streams (regardless of role, environment, or location), and quickly search for, aggregate, and pivot between data points."
To make the most of this, adopt a clear tagging strategy. Below is an example of a tagging structure commonly used by SMBs:
| Tag Category | Example | Purpose |
|---|---|---|
| Environment | env:production |
Distinguish between development, staging, and production |
| Location | datacenter:us1.prod |
Monitor performance by data center |
| Service | service:web-store |
Identify specific applications |
| Business Unit | business_unit:internal-processing |
Track resource usage by department |
| Cost Center | cost_center:internal-processing-01 |
Manage and monitor expenses |
Organizing Key Infrastructure Details
Document essential infrastructure details in the Service Catalog. Include information like service owners, team contacts, on-call personnel, and dependencies to streamline incident response.
Configuring Alerts
Set up dynamic alerts using tag variables. This ensures notifications are automatically routed to the appropriate service owners. In complex environments, proper tagging helps teams quickly isolate issues by narrowing down to specific regions or services.
Alert Setup and Response
Setting up effective alerts is key to maintaining system health and resolving issues quickly. Datadog provides a structured alerting system that helps small and medium-sized businesses handle different levels of severity without overwhelming their teams.
Alert Severity Levels
Datadog categorizes alerts into three tiers to ensure timely and appropriate responses:
| Severity Level | Notification Method | Examples | Expected Response Time |
|---|---|---|---|
| Low | Logging Only | Minor latency spikes, slow query performance | Handle during business hours |
| Moderate | Email/Chat | Disk space warnings, degraded performance | Respond within 2–4 hours |
| High | Paging/Phone | Service outages, critical errors | Immediate response |
Configuring Smart Alerts
Focus alerts on symptoms that directly affect customers, not just technical metrics like CPU usage. For instance, set up alerts for scenarios like "90% of web requests taking over 0.5 seconds to process". To stay ahead of resource issues, configure early warnings for disk usage at 70% and critical alerts at 85%.
Integrating with Response Tools
Datadog simplifies incident response by integrating with popular tools. Ben Edmunds, Staff Engineer at SeatGeek, explains:
"It's easier to find information because everything's all in one place and documented throughout the process. If you have a problem today, you can look and see when a similar issue happened before, helping you resolve that issue faster."
Pair these integrations with on-call protocols to complete your response strategy.
Automated Response Workflows
Datadog offers several automation features to streamline alert management:
- Map service dependencies using the Datadog Software Catalog.
- Link alerts directly to Slack or Microsoft Teams for instant collaboration.
- Use the Datadog Mobile App to address issues remotely and efficiently.
On-Call Management
Torc Robotics highlights the benefits of Datadog's integrated on-call management. Matthew Green, Staff Engineer, shares:
"With Datadog On-Call we now have integrated observability, paging and incident response in one platform that helps us get the right person involved with a page as fast as possible to triage product stability."
Set up clear on-call schedules and routing rules. Leverage tags like {{#is_alert}} and {{#is_warning}} to ensure notifications reach the right team members.
Alert Best Practices
Before creating an alert, consider these questions:
- Is the issue actionable?
- Does it require human intervention?
- Does it need an immediate response?
Alexis Lê-Quôc from Datadog underscores the importance of automated alerts:
"Automated alerts are essential to monitoring. They allow you to spot problems anywhere in your infrastructure, so that you can rapidly identify their causes and minimize service degradation and disruption."
Keep a centralized log of all alerts to identify patterns and improve system performance over time.
Dashboard and Metrics Setup
Key Metrics for Small and Medium Businesses (SMBs)
Choose Datadog metrics that align with your SMB objectives:
| Metric Category | Key Measurements | Business Impact |
|---|---|---|
| Infrastructure | CPU, Memory, Disk Usage | Plan resource allocation |
| Application | Response Time, Error Rate | Improve user experience |
| Business | Transaction Volume, User Sessions | Drive revenue growth |
| Security | Failed Login Attempts, Access Patterns | Manage risks |
Once you've identified these metrics, design dashboards that make it easier to track and interpret this data.
Building Targeted Dashboards
Organize your dashboards into focused sections for better clarity:
1. Infrastructure Overview
Use widgets to highlight system health. Include insights on resource trends, network performance, server response times, and the number of active instances.
2. Application Performance
Create panels that focus on:
- Service latency
- Error rates by endpoint
- Database query speeds
- Cache hit ratios
3. Business Metrics
Showcase metrics that reflect your business's success, such as:
- Active user counts
- Transaction success rates
- API call volumes
- Metrics tied to revenue generation
Adding Custom Metrics
Go beyond the default metrics by setting up custom ones that reflect your specific business needs. Examples include:
- Patterns in user engagement
- Success rates for payment processing
- Adoption rates for specific features
- Compliance with service-level agreements (SLAs)
Tips for Organizing Dashboards
Keep your dashboards tidy by grouping related metrics, using consistent naming conventions, and applying clear, descriptive titles. Assign appropriate time ranges to each metric for better insights.
Choosing the Right Visualizations
Match your data type with the best visualization format:
| Data Type | Recommended Visualization | Best For |
|---|---|---|
| Time-series | Line graphs | Tracking resource usage trends |
| Percentages | Gauge charts | Monitoring capacity levels |
| Counts | Bar graphs | Highlighting error occurrences |
| Distributions | Heat maps | Analyzing response time patterns |
Tracking Performance Baselines
Establish performance baselines to spot anomalies early. Use these techniques:
- Compare current data with historical trends
- Monitor peak usage periods
- Account for seasonal changes
- Track growth patterns
These baselines not only help validate trends in your dashboards but also improve the accuracy of your alert configurations.
Security and Compliance Tools
Datadog offers features designed to help SMBs safeguard their infrastructure and stay aligned with compliance requirements. This streamlined approach boosts both security and operational performance.
Threat Detection and Response
Datadog Cloud SIEM leverages more than 900 detection rules based on the MITRE ATT&CK® framework, enabling real-time analysis of security data across your infrastructure.
| Security Feature | Business Benefit | Implementation Priority |
|---|---|---|
| Cloud SIEM | Detect threats in real time | High |
| Detection Rules | Automate monitoring | High |
| Compliance Frameworks | Adhere to industry standards | Medium |
| Security Analytics | Minimize risks | Medium |
Compliance Management
Datadog ensures adherence to key industry standards, including:
- CIS benchmarks
- PCI DSS
- SOC 2
- HIPAA
Agentless scans work continuously to uncover vulnerabilities, misconfigurations, and compliance issues. Additionally, Datadog integrates seamlessly with your tech stack to extend these benefits across your entire environment.
Integration Capabilities
Datadog supports over 850 vendor integrations, providing a unified view of your technology stack. This includes compatibility with major cloud platforms like AWS, Azure, and Google Cloud, all accessible through a single dashboard.
"Datadog gives me confidence that we know where our entire organization sits from a security standpoint, as well as a simple way to show senior leadership measurable improvements to our security posture that result from our collective efforts."
- Kelly Bettendorf, Security Engineer, Stavvy
Cost-Effective Logging
Datadog's Logging without Limits™ pricing model allows SMBs to:
- Collect all logs at a low cost
- Analyze logs in real time
This pricing approach complements Datadog's proactive security features, making comprehensive logging more accessible.
Security Investigation Tools
Datadog's investigation dashboards help teams:
- Monitor unauthorized access attempts
- Track configuration changes
- Detect potential threats
- Examine security incidents in depth
"At Instacart, we care about unauthorized access, and with Datadog's Cloud SIEM we've been able to track down malicious third parties and protect our users more quickly."
- Blaine Schanfeldt, Site Reliability Engineer, Instacart
Automated Response Workflows
Datadog streamlines security responses by automating tasks like ticketing, team communication, remediation, and case management. This automation reduces response times and enhances collaboration during incidents.
"Datadog enables near real-time tracking of activity for 1Password's security engineering team. The detection rules are intuitive and easy to understand and it's easy to onboard new team members. I love Datadog, it's not just a log management tool, it's a holistic observability and security Swiss Army Knife."
- Mel Masterson, GCIH, GCWN, Information Security Engineering Manager, 1Password
Resource and Cost Management
Datadog helps businesses manage resources effectively while keeping cloud costs under control. By leveraging data insights, it not only reduces expenses but also complements performance and security monitoring, which is crucial for small and medium-sized businesses (SMBs).
Spotting Opportunities to Save
Datadog Cloud Cost Management examines usage trends to pinpoint areas where costs can be reduced. For example, the platform identified an unused RDS instance that had been sitting idle for over 60 days. Removing it saved $1,800 every month.
Optimizing Kubernetes Costs
Datadog's Kubernetes Autoscaling tackles inefficiencies by:
- Offering detailed scaling recommendations
- Identifying unused resources and their costs
- Automating workload adjustments
- Supporting both horizontal and vertical pod autoscaling
Between 2023 and 2024, Kubernetes workloads saw a slight drop in median CPU usage, from 16.33% to 15.9%. This suggests there’s room to adjust resources more effectively.
Planning Ahead with Predictive Tools
Once container efficiency is addressed, planning for future capacity becomes essential. Datadog uses machine learning to analyze historical data and help with:
-
Predicting Resource Limits
Identifying when resources are likely to run out. -
Factoring in Usage Trends
Accounting for seasonal shifts, such as daily or weekly spikes in API requests. -
Adjusting to Changes
Automatically updating forecasts to reflect major shifts in usage patterns.
Automating Cost-Saving Efforts
With Datadog App Builder, SMBs can create custom automation for managing AWS environments. This tool makes it easier to identify and clean up unused resources, ensuring efficient allocation. These automation features simplify cloud operations and help businesses maintain cost-effective setups.
Monitoring Maintenance
Keeping your Datadog setup in shape requires regular reviews. These reviews ensure your configuration stays aligned with your SMB's changing needs, maintaining accuracy and timely responses over time.
Setting Review Schedules
Plan routine evaluations of your monitoring settings to keep everything running smoothly:
-
Alert Configuration Assessment
Check that alerts signal real, actionable, and urgent issues - not noise. -
Threshold Adjustments
Fine-tune thresholds to avoid unnecessary alerts. For instance, if a disk space alert triggers at 90% capacity, set the recovery threshold at 85% to prevent repeated notifications. -
Automated Responses
Automate responses for common issues to save time and ensure quick resolutions.
Maintenance Best Practices
Focus on metrics that directly impact the end-user experience. This helps you catch and resolve user-facing problems more effectively.
| Alert Priority | Purpose | Response Time |
|---|---|---|
| Record Only | Historical tracking | No immediate action |
| Notification | Team awareness | Within business hours |
| Page | Urgent response | Immediate attention |
Leveraging New Features
Use Datadog's Recommended Monitors to simplify your setup with pre-built, industry-standard alerts. These monitors offer:
- Predefined alert queries for essential infrastructure
- Adjustable thresholds based on industry guidelines
- Proactive monitoring to catch issues early
- Alerts with relevant context for better precision
By centralizing your alert logs, you can integrate these features seamlessly into your ongoing monitoring efforts.
Centralizing Alert Management
Store all alert logs in one place to improve visibility and identify trends over time. This helps you connect the dots between metrics and events, making your monitoring strategy more effective overall.
1. Set Disk Space Alerts
Keeping an eye on disk space is essential to prevent service disruptions. Use Datadog monitors to track storage usage effectively.
Setting Alert Thresholds
A tiered alert system can help you address storage issues before they escalate:
| Alert Level | Threshold | Action |
|---|---|---|
| Warning | 75% usage | Schedule cleanup tasks |
| Critical | 85% usage | Take immediate action |
| Emergency | 95% usage | Trigger automated responses |
Using Smart Alerts
To catch unusual storage trends, enable anomaly detection. Configure your monitor to track:
- Absolute Usage: Keep tabs on the total storage consumed (e.g., in gigabytes or terabytes).
- Growth Rate: Monitor how quickly storage is being used over time.
Dynamic Thresholds
Review the last 30 days of disk usage to establish dynamic baselines. This helps reduce false alarms and adjusts for natural growth patterns.
Steps to Configure Alerts
-
Choose Metrics
- Use
system.disk.in_usefor percentage-based monitoring. - Add
system.disk.usedto track absolute storage usage.
- Use
-
Set Conditions
- Configure a warning alert at 75% usage.
- Set critical alerts for 85% usage.
- Enable forecast monitoring to predict potential storage problems.
-
Add Context
- Include details like disk location, server name, runbook links, and team ownership in your alerts.
Proper disk space monitoring is essential for maintaining system performance. This targeted alerting approach works alongside broader monitoring practices, setting the stage for further optimization.
2. Use Tags to Group Resources
Tagging is a practical way to improve infrastructure monitoring. A well-thought-out tagging system allows small and medium-sized businesses (SMBs) to quickly locate, monitor, and resolve issues across their technology stack. It complements earlier efforts like setting up alerts and dashboards, making monitoring more streamlined and effective.
Key Tag Categories
| Tag Type | Purpose | Example Tags |
|---|---|---|
| Infrastructure | Monitor cloud resources | account, region, instance-type |
| Environment | Define deployment stages | prod, dev, staging |
| Business | Connect to business operations | team, department, cost-center |
| Application | Aid in operational troubleshooting | component, service-name, version |
Datadog makes tagging easier by automatically importing tags for AWS resources. These include details like availability zone, instance type, auto-scaling group, and region.
Custom Tagging Strategy
To improve visibility, consider setting up custom tags in the Datadog Agent configuration. Focus on these areas:
- Service Classification: Assign tags based on a service's role and purpose to simplify filtering during incidents.
- Team Ownership: Include team-related details such as:
- Team name
- On-call rotation
- Service owner
- Performance Tracking: Aggregate performance metrics with tags to spot trends and troubleshoot more efficiently.
Best Practices
Stick to platform-specific tagging guidelines for consistency. For Kubernetes deployments, use standard labels like:
componentmanaged-bynamepart-of
Keep your tagging system straightforward yet thorough. Tags help link metrics, traces, and logs, making it easier to identify and solve issues during troubleshooting. Use tools like the Service Catalog to document who owns what, ensuring clear communication between teams. A well-organized tagging system not only simplifies day-to-day operations but also enhances performance monitoring and issue resolution down the line.
3. Build SMB-Focused Dashboards
Customizing dashboards for SMBs helps highlight trends and pinpoint issues quickly, making troubleshooting faster and more efficient. Here's how to tailor your dashboard setup to meet these needs.
Key Dashboard Components
| Widget Type | Best Use Case | Key Benefit |
|---|---|---|
| Timeseries | Track performance metrics over time | Monitor trends and patterns effectively |
| Query Values | Display critical system metrics | Quick status checks with visual cues |
| Host Maps | Provide an infrastructure overview | Visualize overall system health |
| Top Lists | Rank resources | Spot outliers and bottlenecks easily |
| Alert Graphs | Monitor alerts in real time | Stay updated on system statuses |
Organizing Dashboards
To ensure clarity and usability, organize dashboards into these categories:
- System Health: Focus on core metrics like CPU usage, memory, and disk I/O.
- Application Performance: Track metrics tied to specific services that impact daily operations.
- Resource Optimization: Highlight capacity trends and usage patterns to manage costs effectively.
Tips for Effective Visualization
"Creating effective dashboards is both an art and a technical science. If you have an excellent way of collecting data but with no impressionable way to present it to stakeholders, then it's likely to not get the expected business outcome." - Anaflor Pernalete, Data Enthusiast
- Use line graphs to monitor single metrics over time.
- Apply stacked graphs to illustrate relationships between metrics.
- Leverage heat maps for distribution analysis.
- Add markers to indicate acceptable ranges.
- Use conditional formatting for real-time status updates.
Dynamic Features for Dashboards
Make your dashboards flexible by incorporating dynamic elements. Use template variables to filter data based on:
- Environment tags
- Service names
- Team assignments
- Time ranges
Including context and documentation alongside your dashboards ensures stakeholders understand the data at a glance.
4. Track Live Performance Data
Keeping an eye on live performance data is key to maintaining uninterrupted service. Datadog's Live Processes feature delivers system metrics with a two-second refresh rate, offering a clear view of what's happening in real time. Below are some metrics that can help you better understand your system's performance.
Key Performance Metrics
| Metric Type | What to Monitor | Why It Matters |
|---|---|---|
| CPU Usage | Process-level consumption | Highlights resource-heavy processes |
| Memory | Active and cached memory | Helps avoid system slowdowns |
| Thread Count | Process thread allocation | Ensures smoother application performance |
| Resource Use | System-wide utilization | Aids in scaling infrastructure |
Setting Up Real-Time Monitoring
To make the most of live monitoring, focus on these areas:
- Process-Level Insights: Keep tabs on individual processes to catch unexpected spikes in resource usage.
- System Metrics: Monitor CPU, memory, and disk I/O across your entire environment.
- Thread Management: Watch thread counts to avoid potential bottlenecks.
Integrating live monitoring with your alerts and dashboards creates a more complete monitoring setup.
Real-World Example
"Datadog's unified DevSecOps approach has improved our ability to manage risks, prioritize responses, and remediate issues. As a result, we've been able to reduce tool sprawl and foster a culture of shared security ownership throughout the organization."
– Eric Saam, VP of Engineering, Business Insider
Here's a concrete example: A team using Datadog Live Processes discovered that a SumoLogic log collector was eating up 25% of CPU resources, while an AWS Kinesis producer was using more than 100 threads. This highlights how real-time monitoring can help you spot and resolve performance issues before they escalate.
Tips for Optimization
Use conditional alerts, monitor resource trends, analyze process dependencies, and filter by hosts or zones. These strategies can make live monitoring more effective and easier to manage.
5. Connect with Issue Management
Link Datadog alerts to incident management tools to speed up how quickly issues are resolved. By combining well-configured alerts with incident management workflows, teams can address problems more effectively. This connection ensures monitoring data flows seamlessly into response processes, cutting down resolution times and improving teamwork.
Setting Up Incident Management
Once your alerts are fine-tuned, centralize your incident management tools to simplify responses. Datadog's platform brings everything together in one place:
| Component | Function | Benefit |
|---|---|---|
| Alert Integration | Links with Slack, Teams, Jira | Quick team notifications |
| On-Call Scheduling | Manages response rotations | Ensures round-the-clock coverage |
| Automated Runbooks | Standardizes response procedures | Minimizes human errors |
| Mobile Access | Enables remote troubleshooting | Faster reaction times |
Customizing Your Response Workflow
Fine-tune your notification rules by considering factors like:
- Severity levels of incidents
- Impacted service categories
- Specific resource names
- Identified root causes
This focused method ensures the right people get the right alerts, avoiding unnecessary noise or alert fatigue. Many teams have seen success with this approach in real-world scenarios.
Real-World Success Stories
Companies using Datadog's incident management tools have reported impressive results:
"When Datadog released On-Call and Incident Management, we saw the benefit of using these tools alongside APM to give engineers one place to monitor performance, schedule our rotations, and streamline our workflow." - Chris Waters, CTO at Aha!
SeatGeek highlights the value of historical data for faster troubleshooting:
"It's easier to find information because everything's all in one place and documented throughout the process. If you have a problem today, you can look and see when a similar issue happened before, helping you resolve that issue faster." - Ben Edmunds, Staff Engineer at SeatGeek
Maximizing Incident Response
To get the most out of your incident management setup, consider these steps:
- Use Datadog Notebooks to document automated postmortems
- Share monitoring data directly in Slack or Teams
- Assign teams to specific services for automatic alert routing
- Analyze response times and patterns to improve future workflows
6. Plan Capacity Using Past Data
After setting up monitoring and maintenance strategies, the next step is capacity planning. This involves using historical data to predict future resource needs. With Datadog's machine learning (ML) forecasting, you can analyze trends and plan accordingly. Datadog retains process metrics for up to 15 months, making it easier to identify patterns and prepare for growth.
Understanding Forecast Patterns
Datadog's forecasting algorithms identify:
- Daily and weekly usage trends
- Seasonal variations
- Shifts in baseline metrics
- Long-term growth patterns
These insights allow businesses to plan resources in advance, avoiding last-minute issues.
Setting Up Resource Forecasting
Focus on monitoring these key metrics for effective capacity planning:
| Metric Type | What to Monitor | Planning Benefit |
|---|---|---|
| Infrastructure | Disk space, CPU usage | Avoid resource shortages |
| Application | API requests, response times | Scale services ahead of demand |
| Business | Active users, transaction volume | Prepare for growth |
Using Historical Data Effectively
Make the most of Datadog's 15-month data retention by focusing on these actions:
-
Tracking Process-Level Details
Use unified tagging to monitor applications and services, identifying patterns and evaluating deployments. -
Setting Up Forecast Alerts
Create alerts to warn your team before resources reach critical thresholds. -
Analyzing Seasonal Trends
Study recurring patterns, such as time-of-day or day-of-week variations, to prepare for predictable demand spikes. Datadog automatically adjusts for these fluctuations.
By leveraging these features, you can fine-tune your capacity planning over time.
Best Practices for Historical Metrics
Enable historical metrics ingestion to ensure accurate, long-term data collection. This data is useful for:
- Filling gaps after outages
- Validating your planning assumptions
- Making better scaling decisions
Real-World Application
Set up dashboards that combine historical trends with forecast data. For example, if you're monitoring API requests, you can visualize time-of-day patterns and predict when to scale up resources.
Add forecast visualizations to team dashboards to streamline discussions on:
- Resource usage trends
- Future capacity needs
- Budget allocation
- Infrastructure improvements
Incorporating these forecasting methods into your strategy ensures you stay ahead in managing resources effectively.
7. Set Up Security Monitoring
Effective security monitoring is essential for SMBs to detect and respond to threats while staying compliant. Datadog's security tools make this process more manageable and efficient.
Key Security Features
Here are some critical components to consider:
| Component | Purpose | Benefit |
|---|---|---|
| Cloud SIEM | Detect and investigate threats | Real-time monitoring |
| App Protection | Monitor application security | Identifies potential risks |
| CloudTrail Logs | Track activity | Provides an audit trail |
| IaC Scanning | Analyze infrastructure code | Prevents configuration errors |
Fine-Tuning Threat Detection
To enhance threat detection, adjust alert settings to match your security needs. Datadog offers over 900 pre-configured detection rules aligned with the MITRE ATT&CK framework. These rules provide a strong starting point for monitoring and alerting.
Automating Incident Responses
Save time by automating responses to recurring incidents. Constantine Macris, CISO at Indigov, highlights the benefits:
"Datadog is by far the easiest and most integrated platform to get all of our disparate data into one spot. Datadog reduces the mean time to respond from hours down to minutes! Out-of-the-box detection rules help get from 0 to operations quickly."
Compliance Monitoring Tools
Datadog's Cloud Security Management simplifies compliance with features like:
- Continuous scanning of infrastructure
- Automated compliance checks
- Real-time alerts for violations
- Dashboards for compliance reporting
Best Practices for Security Integration
- Deploy Security Agents: Install and configure the Datadog Agent across all systems to collect security data.
- Set Access Controls: Limit and manage access to security settings to balance collaboration and protection.
- Leverage Threat Intelligence: Use Datadog's threat intelligence tools to identify and address new risks. The 1Password security team shares:
"Datadog enables near real-time tracking of activity for 1Password's security engineering team. The detection rules are intuitive and easy to understand and it's easy to onboard new team members. I love Datadog, it's not just a log management tool, it's a holistic observability and security Swiss Army Knife."
Building Monitoring Dashboards
Design dashboards to keep critical security data at your fingertips. Include:
- Active threats
- Compliance status
- Triggered detection rules
- Incident trends
- Response time metrics
These customized dashboards help you stay organized and respond effectively to security challenges.
8. Check Resource Usage Reports
Reviewing resource usage is essential for optimizing Datadog performance and managing cloud costs effectively. This involves tracking critical metrics and making adjustments based on usage data.
Key Metrics to Monitor
| Metric Type | What to Monitor | Why It Matters |
|---|---|---|
| CPU Usage | kubernetes.cpu.usage.total |
Identifies processing bottlenecks |
| Memory Usage | Live Process data | Helps avoid resource shortages |
| Container Resources | Pod utilization | Ensures resources are appropriately sized |
| Component Usage | Dashboards and monitors | Reduces unnecessary resource use |
Strategies for Better Resource Management
- Start with conservative allocations for new services to gather accurate usage data without risking performance issues.
- Use Kubernetes Vertical Pod Autoscaler with Datadog to get resource recommendations for better efficiency.
Memory Management Tips
Setting proper memory limits is crucial for stable service operations. For instance, CloudNatix's integration with Datadog highlights how effective memory management can minimize resource conflicts and reduce costs. Once memory limits are optimized, you can move on to analyzing broader resource usage trends.
Steps for Resource Analysis
- Track historical CPU and memory usage trends and create percentile-based reports.
- Identify and review underutilized components.
- Adjust resource allocations based on observed usage patterns.
Example: Optimizing MySQL Deployments
A real-world case involves monitoring MySQL deployments. By tracking the mysqld process, a p95 memory usage peak of 821 MiB was observed, compared to a 750 MiB container request. This revealed the need to increase memory allocation to prevent performance issues.
Fine-Tuning for Efficiency
Regularly refine your Datadog setup to cut costs and improve observability. This includes removing unused components and adjusting resource allocations as needed.
9. Reduce Alert Frequency
Too many alerts can overwhelm your team, making it harder to focus on critical issues. This is known as alert fatigue. When your monitoring system sends excessive notifications, essential alerts can get buried in the noise.
For example, one organization experienced a flood of 4,000 alerts in just 30 minutes due to a network configuration error. Using Datadog's Event Management system, they condensed these alerts into a single notification, cutting through the chaos and restoring clarity.
Fine-tuning your alert settings can help prevent similar situations.
Smart Alert Configuration
| Alert Type | Configuration Tip | Expected Outcome |
|---|---|---|
| Service Checks | Notify only after multiple failures | Cuts down on false positives |
| Performance Alerts | Extend the evaluation window | Avoids alerts triggered by short spikes |
| Related Issues | Group notifications for similar alerts | Reduces redundant notifications |
| Maintenance Events | Schedule downtime periods | Suppresses alerts during planned work |
Steps to Reduce Unnecessary Alerts
To avoid drowning in irrelevant notifications while still catching critical issues, try these approaches:
- Recovery Thresholds: Define clear recovery conditions to stop alerts from repeatedly switching between healthy and unhealthy states.
- Evaluation Windows: Use longer evaluation periods to analyze more data before triggering alerts, filtering out temporary fluctuations.
- Automated Responses: Automate fixes for routine problems to eliminate the need for manual intervention and reduce alert volume.
These steps complement the alert configuration tips outlined above.
Managing and Routing Alerts Effectively
Group related alerts by service type, cluster, or device category to maintain context while reducing the total number of notifications. Once grouped, route alerts conditionally to ensure they reach the right person or team. Tailor alert delivery using variables like severity level, time of day, team roles, and the impact on services.
"Alert fatigue occurs when an excessive number of alerts are generated by monitoring systems or when alerts are irrelevant or unhelpful, leading to a diminished ability to see critical issues." - Datadog
10. Use Datadog Learning Resources
Mastering Datadog can significantly boost your team's efficiency. To help with this, Datadog provides a wide range of learning resources tailored for SMB teams.
Learning Center Overview
The Datadog Learning Center (updated March 31, 2025) offers structured paths to help users develop expertise in specific areas:
| Learning Path | Courses | Focus Areas |
|---|---|---|
| Core Skills | 5 | Navigation, tagging, metrics, monitors, dashboards |
| Configuration | 5 | Agent setup, integrations, Universal Service Monitoring (USM), tagging |
| Backend Engineer | 3 | Application Performance Monitoring (APM), log exploration, infrastructure monitoring |
| Fundamentals Certification | 15 | Platform basics and certification preparation |
Role-Based Training
The Learning Center also offers training paths tailored to specific roles, with over 80 courses to choose from. These include:
- Troubleshooting APM instrumentation
- Setting up Universal Service Monitoring
- Detecting web application attacks using App & API Protection
- Getting started with Service Level Objectives (SLOs)
- Creating custom metrics with DogStatsD
These role-specific paths allow teams to focus on what’s most relevant to their responsibilities.
Getting Started with Datadog Training
Here’s how to make the most of Datadog’s learning resources:
- Start with Core Skills: This path lays the groundwork by covering essential features like tagging, dashboards, and monitors.
- Move to Specialized Courses: Once the basics are covered, dive into role-specific training. For example, the Backend Engineer path focuses on APM, log exploration, and infrastructure monitoring.
Community Support
For additional help, join the #learning-center Slack channel. It’s a great place to connect with Datadog experts and other users for real-time advice.
Alert Methods Comparison
Explore key alert methods to maintain system reliability without overwhelming your team.
Alert Types and Their Applications
| Alert Type | Best For | Key Benefits | Considerations |
|---|---|---|---|
| Threshold-Based | Static metrics with clear limits | Easy to set up and provides predictable triggers | May not work well with fluctuating metrics |
| Anomaly Detection | Dynamic workloads and seasonal patterns | Adjusts to metric changes and minimizes false alarms | Needs historical data for accuracy |
| Tiered Alerts | Mixed-priority monitoring | Routes alerts by importance to reduce noise | Requires clear definitions for severity levels |
Optimizing Alert Delivery
How you deliver alerts plays a big role in their effectiveness. For small and medium-sized teams, using multiple communication channels can improve response times:
Critical Issues (High Priority)
- Use tools like PagerDuty for instant notifications.
- Set up escalation policies for unacknowledged alerts.
- Include detailed context in alerts to speed up resolution.
Warning Alerts (Medium Priority)
- Send alerts to Slack channels for team-wide visibility.
- Encourage real-time collaboration to address issues quickly.
- Group related alerts to cut down on noise.
Informational Alerts (Low Priority)
- Use email for non-urgent notifications and documentation.
- Combine alerts into daily or weekly summaries.
- Leverage these alerts for tracking trends and long-term insights.
Smart Alert Configuration
To make alerts more effective and reduce unnecessary noise:
- Extend evaluation periods to filter out short-term spikes.
- Set recovery thresholds to confirm that issues are resolved before clearing alerts.
- Use exponential backoff for retry attempts to avoid overwhelming the system.
These steps help align your alerts with your overall monitoring strategy, ensuring you stay informed without being overwhelmed.
Practical Alert Implementation
Tiered alerting allows you to assign different severity levels within a single monitor. Take HAProxy frontend denial rates as an example:
- Set a warning threshold at 25 requests per minute to notify the Slack operations channel.
- Set a critical threshold at 50 requests per minute to send an email directly to the responder.
This setup ensures minor issues are handled without disrupting operations, while major problems get immediate attention.
Advanced Alert Management
For more complex environments, consider these advanced strategies:
- Dynamic Workloads: Tools like Datadog's anomaly detection automatically choose the best algorithm based on historical data.
- Microservices:
- Map out service dependencies to anticipate potential alert chains.
- Group related alerts to streamline notifications.
- Schedule maintenance windows to silence alerts during planned downtime.
- Automate responses for known issues to save time and resources.
Conclusion
Using Datadog effectively can play a key role in helping SMBs thrive. Start by setting up a solid foundation and creating real-time dashboards that offer instant insights into system health and performance metrics.
Companies like Whatnot have shown how end-to-end visibility can make a difference. As Cloud Engineer Chris Peraza explains:
"Datadog APM enables our developers to see the entire path from our iOS and Android clients all the way down to services they have built"
To make the most of your monitoring budget, consider these strategies:
- Focus on collecting only the most relevant data
- Use anomaly detection to catch issues early
- Implement tiered alerting to avoid overwhelming your team
- Prioritize metrics that directly impact your business
These steps not only help control costs but also set the stage for a resilient infrastructure. Zach McCormick, Engineering Manager at Braze, highlights the value of this approach:
"When debugging performance problems across billions of emails and push notifications, we need access to all live tracing data. Datadog's tracing tools have been invaluable for troubleshooting"
Make it a habit to review and adjust your monitoring strategy regularly to keep up with changing requirements. By sticking to these practices, you can maintain reliability, optimize performance, and manage costs effectively.
FAQs
How can SMBs reduce alert fatigue while using Datadog for monitoring?
To reduce alert fatigue with Datadog, SMBs should focus on fine-tuning their monitoring strategy. Start by reviewing and adjusting noisy alerts, such as those that are overly sensitive or frequently change status. You can increase evaluation windows, set recovery thresholds, or suppress alerts during planned maintenance to prevent unnecessary notifications.
Another effective tactic is grouping similar alerts to avoid overwhelming your team with redundant messages. Use conditional variables to tailor notifications based on specific criteria, ensuring they’re actionable and relevant. By prioritizing meaningful alerts and ensuring they provide clear context, SMBs can maintain focus on critical issues without being overwhelmed.
What are the best practices for creating dashboards in Datadog to make key metrics easy to access and act on for SMBs?
To create effective dashboards in Datadog for SMBs, start by identifying the specific metrics and insights that matter most to your business operations. Focus on the questions you frequently ask about system performance and customer experience, and design your dashboards to provide clear answers.
Use a mix of widgets like time series graphs for trends, query values for quick snapshots of key metrics, and tables for detailed lists. Organize the layout logically, grouping related metrics together, and use headings or labels for clarity. Regularly review and update your dashboards to ensure they stay relevant, removing outdated widgets or unused dashboards to keep things streamlined.
By tailoring dashboards to your needs and maintaining a clean, organized structure, you can make critical data more actionable and accessible, helping your SMB achieve better visibility and operational success.
How can Datadog's machine learning features help SMBs with capacity planning and resource management?
Datadog's machine learning capabilities empower small and medium-sized businesses (SMBs) to optimize capacity planning and resource management by leveraging advanced forecasting algorithms. These tools analyze historical trends and real-time data to predict future resource needs, enabling teams to proactively address potential issues like running out of disk space or exceeding system limits.
By providing timely, data-driven alerts, Datadog helps SMBs maintain smooth operations, avoid costly downtime, and ensure their infrastructure is prepared to scale effectively. This proactive approach saves time, reduces manual effort, and supports better decision-making for growing businesses.



